LLM 정렬의 새로운 돌파구, ‘모델 서저리’ 등장! 🧠✂️
복잡하고 비용이 많이 드는 재학습 없이도
대형 언어 모델(LLM)의 유해한 행동을 줄이는 혁신적 기법이 나왔습니다.
그 이름은 바로 모델 서저리(Model Surgery)
정말 외과 수술처럼, 모델 내부의 특정 파라미터만 정밀하게 수정합니다.
---
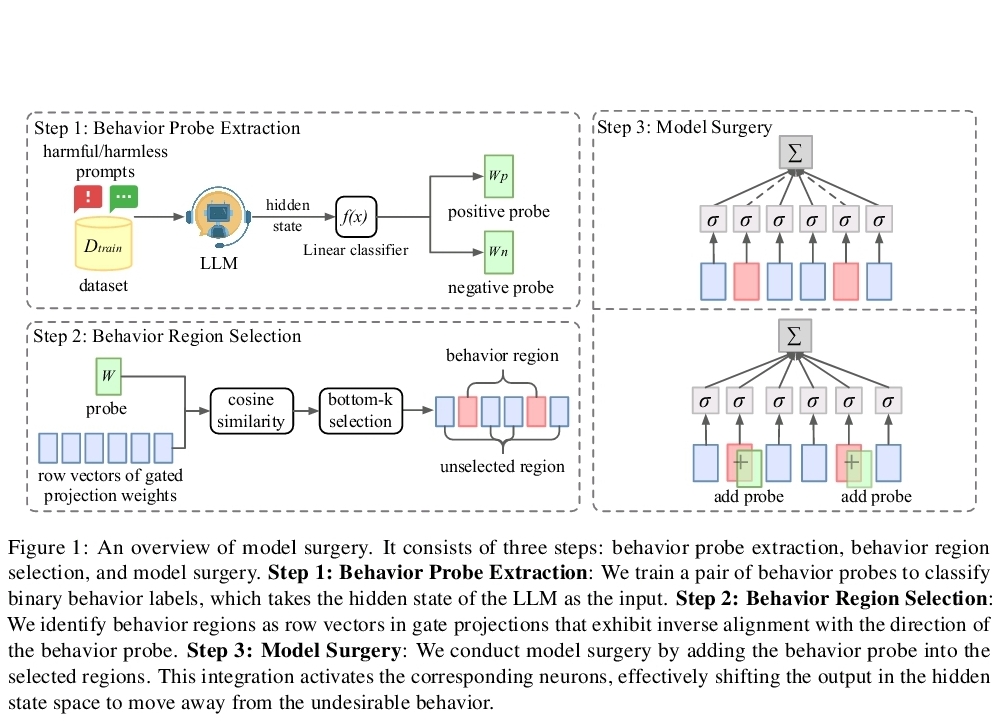
모델 서저리란?
유해성, 탈옥(jailbreak) 등 문제 행동을 일으키는 일부 내부 파라미터만 조정하여 모델의 출력을 변화시키는 방식입니다.
⚡ 빠르고
🧩 계산 자원도 적게 들고
✅ 성능 손실 없이 효과적입니다.
---
작동 방식:
1. 먼저 행동 프로브라는 간단한 분류기를 훈련해 유해한 행동을 감지합니다.
2. 모델의 은닉 상태(hidden state) 중 문제 행동과 관련된 방향성을 찾아냅니다.
3. MLP 층에서 해당 방향성과 반대 정렬된 벡터들을 선택해, 프로브 정보를 더해줍니다.
즉, AI 모델을 ‘행동적으로’ 재조정하는 정밀 수술인 셈이죠.
---
주요 결과:
✔️ 유해성 최대 90% 감소
✔️ 탈옥 방지 능력 향상
✔️ 양방향 제어 가능 – 행동을 추가하거나 제거할 수 있음
✔️ 추론 및 문제 해결 능력 유지
✔️ 다양한 모델에 적용 가능
✔️ 여러 행동을 연속적으로 조정 가능
---
왜 중요한가요?
이 방식은 모델의 안전성을 높이면서도 *정렬 비용(alignment tax)*을 크게 줄일 수 있습니다.
또한, ‘행동’이나 ‘개념’이 LLM 내부에 식별 가능한 형태로 존재한다는 점을 보여줍니다.
하지만 강력한 도구인 만큼, 오남용을 막기 위한 책임 있는 활용이 필수입니다.
---
모델 서저리는 이제 LLM을 더 안전하고 정밀하게 조정할 수 있는 새 시대를 엽니다.
#AI #대형언어모델 #모델서저리 #AI정렬 #LLM #AI안전성 #책임있는AI #모델편집 #유해성감소 #AI연구 #프롬프트엔지니어링